从花讯到路线:基于腾讯位置服务与Agent的城市赏花地图实践——以清华大学春季赏花为例
 松露巧克力手机壳
松露巧克力手机壳
 征文大赛
2026-05-21
征文大赛
2026-05-21
【腾讯位置服务开发者征文大赛】从花讯到路线:基于腾讯位置服务与Agent的城市赏花地图实践——以清华大学春季赏花为例
作者: 松露巧克力手机壳 发布时间: 最新推荐文章于 2026-05-16 11:16:07 发布
来源: https://blog.csdn.net/weixin_44792382/article/details/160585879

摘要
每逢花季,市民往往希望快速了解哪些地点正值花期、如何顺路游览、途中是否便于就餐和休息。然而,现有赏花信息多停留在零散的人工攻略层面(如小红书帖子),难以同时支持动态花况更新、自然语言需求理解和可执行路线生成。围绕这一需求,本文设计并实现了一套面向城市季节性出行场景的城市赏花地图系统,目标是将用户的赏花意图转化为可直接使用、分段清晰的游览路线。
系统以自然语言输入、场景语义解析、候选花点筛选、多阶段路线生成和卡片化结果展示为主链路。在系统设计上,本文将城市赏花地图拆分为基础POI层、季节性花况层、用户共建层和路线反馈层,并通过云端数据库与审核流维护动态花况数据,使地图内容能够随用户提交和花期变化持续更新。在路径规划上,系统引入场景语义工具、Agent任务拆解、候选点裁决与腾讯地图步行规划能力,实现对“看什么花、从哪里出发、是否顺路就餐、是否需要休息、是否优先拍照”等复合约束的多阶段路线生成。在结果表达上,系统输出结构化路线JSON,并将规划摘要、分段路线、POI信息和推荐理由渲染为用户可直接使用的地图卡片。
本文以清华大学春季赏花场景作为验证案例,完整展示了场景建模、路径规划、卡片渲染与用户共建更新链路。该系统虽然以校园场景进行验证,但整体架构面向更大范围的城市季节性赏花服务,具备向城市公园、绿道、景区和多季节花期场景扩展的能力。
相关代码位于:https://github.com/xukaizhao/tsinghua-spring-map
关键词
腾讯位置服务;城市赏花地图;WorkBuddy;Agent;路线规划;花况共建;DeepSeek
文章目录
- 摘要关键词1. 引言2. 基于WorkBuddy与腾讯地图skills的协同开发方式3. 系统目标与总体架构3.1 设计目标3.2 总体架构(1)数据层(2)数据处理层(3)服务层(4)表现层4. 关键技术与实现4.1 季节性花况数据建模与动态聚合4.2 Agent编排与Prompt约束4.3 场景语义工具与候选集构建4.4 多阶段自然语言路线规划4.5 结构化输出与ToolCard渲染4.6 花况共建与云端数据更新5. 案例验证:以清华大学春季赏花场景为例5.1 场景数据与功能组成5.2 典型交互流程5.3 清华大学demo中的核心页面展示(2)花点位与赏花图层(3)自然语言规划面板6. 创新点概括6.1 从零散花讯整合为统一赏花入口6.2 从点位展示扩展为可解释路线规划6.3 从静态花点扩展为动态花况系统6.4 从单一案例扩展为城市级可迁移架构7. 结语
1. 引言
春季赏花是一个典型的高频、短周期、强时令性出行需求。与日常导航相比,赏花出行并不只是“从A点到B点”的路径问题,而是同时包含花期状态、观赏偏好、路线组织、停留节奏和配套服务的综合决策问题。用户在实际使用中往往关心:哪里正值花期、哪里适合拍照、从当前位置过去是否顺路、途中是否便于就餐、最后是否有适合停留休息的地点,以及整条路线大约需要多长时间。
然而,现有地图或出行工具通常更擅长提供POI检索和点到点导航,无法支持赏花这类强时令、强场景化的需求。一方面,花况会随时间快速变化,静态点位难以反映“现在是否值得去”;另一方面,用户的赏花需求往往是复合表达,例如“想看粉色的花,走一段时间,中途吃午饭,最后找个地方休息”,这类需求需要系统同时理解花种偏好、路线阶段、补给需求和终点语义。即使用户已经知道若干赏花点,也仍然需要自行判断点位顺序、补给位置和步行路径,使用成本较高。
因此,面向城市季节性出行的赏花地图需要具备更完整的智能组织能力,至少需要支持以下四项基础能力: 1.对花点、花种、花期状态和观赏属性进行结构化储存与动态更新; 2.对用户复合意图进行可解释的语义拆解,识别观花、拍照、就餐、休息、时长等约束; 3.对候选花点、补给点和休息点进行统一筛选与多阶段路径组织; 4.对路线结果、用户反馈和花况共建数据进行持续更新与前端呈现。
基于上述需求,本文设计并实现了一套面向城市季节性赏花场景的城市赏花地图系统。系统以自然语言输入为入口,结合场景语义工具、Agent任务拆解、候选点裁决、腾讯地图步行规划和ToolCard结果渲染,将用户的赏花意图转化为可直接使用、分段清晰且具备解释依据的游览路线。
本文以清华大学春季赏花场景作为验证案例,围绕以下目标展开系统设计与实现: 1.支持自然语言描述的复合赏花需求解析; 2.支持基础POI、季节性花况、用户共建和路线反馈的分层组织; 3.支持从候选花点筛选到可执行步行路线生成的完整链路; 4.支持结构化路线JSON输出与前端ToolCard可视化呈现; 5.支持从校园验证场景向城市公园、绿道、景区和多季节场景(如秋季赏秋色)扩展。
2. 基于WorkBuddy与腾讯地图skills的协同开发方式
本文在实现过程中采用WorkBuddy作为协作式开发助手,结合腾讯地图相关Skills完成地图能力接入。WorkBuddy主要参与需求拆解、代码生成、Prompt整理、交互联调和结果验证;腾讯地图Skills则为地图初始化、POI检索、逆地理编码、步行规划、坐标系处理和ToolCard展示等功能提供实现参考。
整体开发采用“问题描述—模块拆解—生成原型—读代码修正—联调迭代”的方式推进。首先明确城市赏花地图的产品目标、数据来源和交互要求,再由WorkBuddy结合项目结构生成前端页面、服务端规划逻辑和Agent提示词,最后基于清华大学春季赏花场景不断修正路线逻辑、字段命名和交互细节。整个原型开发周期约为十天。
3. 系统目标与总体架构
3.1 设计目标
围绕城市赏花地图的应用特征,系统重点解决以下五类问题:
- 信息分散问题:赏花信息常常分散在社交平台、群聊截图与非结构化攻略中,缺乏统一入口和统一表达方式。
- 时效性问题:花期、花况、观赏热度与用户上传图像具有明显时间属性,地图内容需要持续刷新。
- 语义理解问题:用户表达往往包含“想看粉色的花、走一段时间、顺路吃饭、最后找个适合休息的地方”这类复合约束,系统需要把它们解析为结构化规划条件。
- 路径组织问题:系统需要把赏花、拍照、补给、休息等各类游客需求组织为真实可行的路径。
- 结果表达问题:地图智能体的结果必须被前端直接消费,因此需要结构化JSON、地图覆盖物与卡片渲染支持。
3.2 总体架构
系统整体采用“分层架构+时序协同”的设计思路。图3-1展示了城市赏花地图的静态分层结构,图3-2展示了从自然语言需求输入到路线生成与ToolCard展示的动态执行流程。
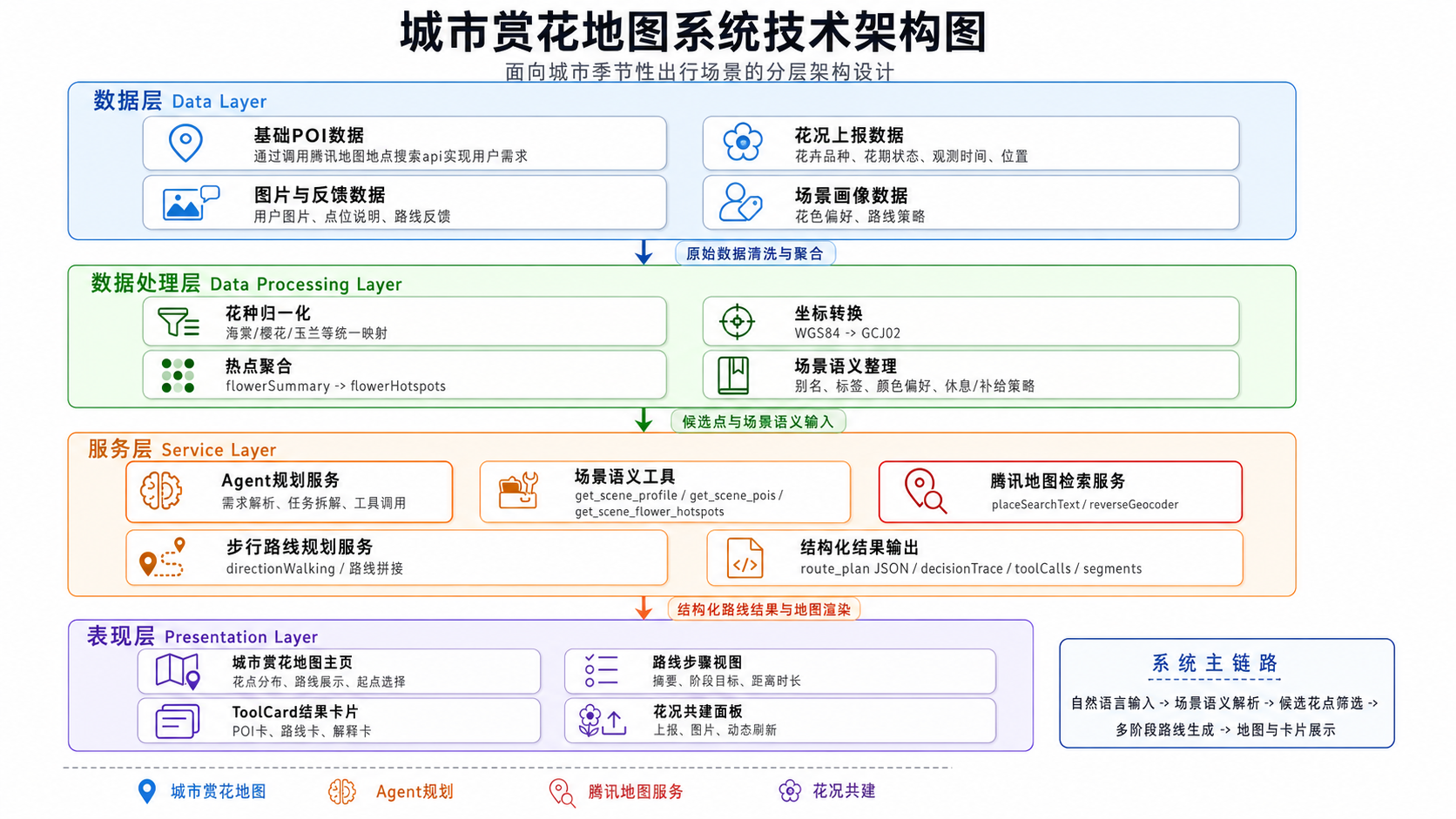
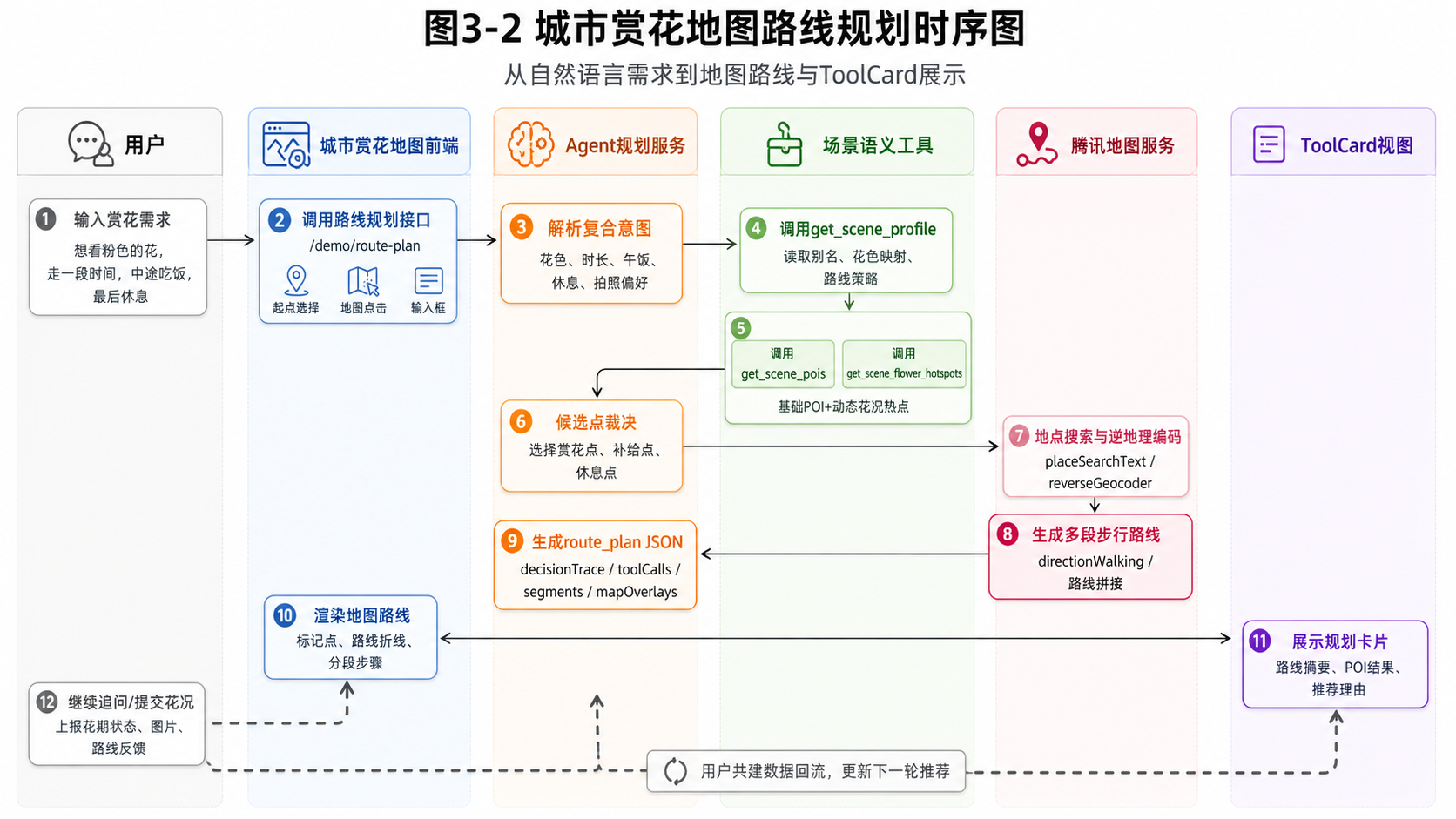
从工程实现上看,系统可划分为数据层、数据处理层、服务层和表现层四个层次;在运行流程上,则通过Agent规划服务、场景语义工具与腾讯地图服务协同完成路线生成。
(1)数据层
数据层负责承载系统运行所需的基础数据与动态更新数据,主要包括基础POI、花况上报、图片与反馈、场景画像等内容。其中,用户共建数据通过云端数据库写入,并进入审核与聚合流程,作为后续推荐和规划的重要依据。
审核通过后的花况数据会进一步聚合为面向规划引擎使用的flowerSummary与热点样本层,用于更新季节点位热度、花期状态和推荐依据。
(2)数据处理层
数据处理层负责将原始数据整理为可供规划服务直接使用的候选对象,主要包括花种归一化、坐标转换、热点聚合和场景语义整理等过程。例如,系统会将不同表述的花种统一映射,将坐标转换为地图服务可用格式,并把花况记录聚合为热点花点集合,同时整理点位别名、标签、颜色偏好和补给策略等场景语义信息。把分散、异构的数据转化为结构清晰、可检索、可规划的输入,为后续路线生成提供统一基础。
(3)服务层
服务层是系统的核心规划层,由路线规划服务承载,对应工程目录为cloudbase-agent-service。其主要职责包括:
- 自然语言需求解析;
- Agent编排与Prompt执行;
- 场景语义工具调用;
- 候选花点、补给点和休息点筛选;
- 腾讯地图检索、逆地理编码与步行路线拼接;
- 结构化路线JSON输出。
在具体流程上,Agent首先解析用户提出的复合需求,再调用get_scene_profile、get_scene_pois和get_scene_flower_hotspots等场景工具获取候选集,随后结合腾讯地图服务完成地点检索、逆地理编码和步行路径规划,最终生成包含decisionTrace、toolCalls、segments和mapOverlays在内的结构化结果。
(4)表现层
表现层负责将规划结果转化为用户可直接使用的地图界面与交互组件,主要包括两部分:
- 基于腾讯地图JS API GL的主地图前端,用于展示花点分布、路线折线、起点选择、花况动态与用户共建入口;
- 基于对话式交互界面与自定义ToolCard的结果视图,用于渲染路线摘要、分段步骤、POI结果和推荐理由。
用户可以继续追问、修改需求,或提交新的花况、图片和路线反馈,这些信息将再次进入数据层与处理层,参与下一轮推荐与规划更新。
4. 关键技术与实现
4.1 季节性花况数据建模与动态聚合
城市赏花地图首先需要解决的是“花况如何表达”。本项目没有把季节性花点处理成固定坐标表,而是将其组织为可更新的热点样本层。服务端cloudbase-agent-service/src/scene-flower-hotspots.ts会从花况摘要中读取样本点,完成花种归一化、坐标转换、标签生成和热点对象构造,核心逻辑如下。
function buildHotspotSummary(summary: FrontendFlowerSummary, index: number) {
const species = normalizeSpecies(summary.species);
if (!species) return [];
return (summary.samples || [])
.map((sample, sampleIndex) => {
const lat = Number(sample?.lat);
const lng = Number(sample?.lng);
if (!Number.isFinite(lat) || !Number.isFinite(lng)) return null;
const coord = wgs84ToGcj02(lat, lng);
const count = Math.max(1, Number(summary.count) || 1);
return {
id: `flower-hotspot-${index + 1}-${sampleIndex + 1}-${species}`,
name: buildHotspotName(species, sampleIndex),
lat: coord.lat,
lng: coord.lng,
aliases: [`${species} 花点`, `${species} 样本点`, `${species} 观赏点`],
species: [species],
tags: getFlowerTags(species),
photoScore: 80 + Math.min(count, 12),
bloomScore: 82 + Math.min(Math.floor(count / 2), 8),
stayMinutes: 6,
clusterSize: count,
} satisfies FlowerHotspot;
})
.filter(Boolean) as FlowerHotspot[];
}
- 将用户共建和聚合统计结果转化为规划引擎可直接使用的候选点;
- 将花况随时间的变化映射为热点强度、花期评分与推荐权重变化;
- 为城市级扩展保留统一数据接口,使不同城市、不同公园可以复用同一套聚合逻辑。
4.2 Agent编排与Prompt约束
本项目的规划服务通过Agent完成任务拆解、工具选择与结果组织。其核心入口位于cloudbase-agent-service/src/agent.ts:
export function createPlannerAgent() {
const model = createPlannerModel();
const checkpointer = new MemorySaver();
return createLangchainAgent({
model,
checkpointer,
tools: createServerTools(),
middleware: [clientTools()],
systemPrompt: SYSTEM_PROMPT,
});
}
规划Agent由四部分组成:
Prompt部分承担了非常关键的“规划规范”作用。在cloudbase-agent-service/src/prompts.ts中,系统明确要求Agent先拆分复合需求,再选择工具,最后输出可渲染的结构化结果。核心片段如下:
export const SYSTEM_PROMPT = `
你是“城市赏花地图Agent”,一个面向春日漫游场景的路径规划智能体。
你的工作流程必须遵守:
1. 先识别用户是否有多个约束
2. 先输出一个脑内任务拆解
3. 如果问题包含校园场景语义,优先调用 get_scene_profile
4. 如果需要先拿候选点,优先调用 get_scene_pois 和 get_scene_flower_hotspots
5. 如果需要补给点或目标点搜索,优先使用腾讯地图搜索类工具
6. 如果已经有多个候选点,优先使用步行路径规划类工具把它们串起来
7. 最终输出要兼顾“解释为什么这么规划”和“可视化渲染所需数据”
`;
Agent在运行时会遵循一条明确链路:先理解需求,再读取场景知识,再调用地图能力,再输出结构化结果。
4.3 场景语义工具与候选集构建
赏花路线规划中的许多信息具有明显场景语义,例如:
- “情人坡”对应休息、草坡、收尾段;
- “万人食堂”对应午饭、补给、中途停留;
- “新清华学堂东侧小路”对应拍照、花路、前半程观赏点;
- “粉色花系”对应樱花、海棠、山桃等候选花种。
这些语义首先在scene-profile.ts中以结构化方式组织:
const SCENES = {
"tsinghua-spring": {
sceneName: "清华大学春日赏花地图",
poiAliases: {
情人坡: ["情人坡", "休息草坡", "适合休息的地方"],
万人食堂: ["万人食堂", "食堂", "午饭", "午餐", "吃饭"],
新清华学堂东侧小路: ["新清华学堂东侧小路", "拍照小路", "花路"],
},
preferredSpeciesByColor: {
pink: ["樱花", "垂丝海棠", "山桃", "桃花", "玉兰"],
white: ["玉兰", "梨花"],
yellow: ["连翘"],
},
routePolicy: {
maxRecommendedStops: 5,
lunchBiasTags: ["食堂", "咖啡", "补给"],
restBiasTags: ["草坡", "长椅", "安静", "树荫"],
},
},
};
随后,这些语义通过server-tools.ts被封装为Agent可调用工具:
export function createServerTools() {
const getSceneProfileTool = tool(
async ({ sceneId }) => {
const profile = getSceneProfile(sceneId);
return JSON.stringify(profile, null, 2);
},
{ name: "get_scene_profile", schema: z.object({ sceneId: z.string().default("tsinghua-spring") }) }
);
const getScenePoisTool = tool(
async ({ sceneId }) => JSON.stringify(getScenePois(sceneId), null, 2),
{ name: "get_scene_pois", schema: z.object({ sceneId: z.string().default("tsinghua-spring") }) }
);
const getSceneFlowerHotspotsTool = tool(
async ({ sceneId }) => JSON.stringify(getSceneFlowerHotspots(sceneId), null, 2),
{ name: "get_scene_flower_hotspots", schema: z.object({ sceneId: z.string().default("tsinghua-spring") }) }
);
return [getSceneProfileTool, getScenePoisTool, getSceneFlowerHotspotsTool];
}
也就是说,场景语义会直接进入规划引擎的实际运行链路:
- Agent先识别出用户需求中的颜色偏好、休息诉求、就餐诉求和终点语义;
- Agent调用场景工具读取颜色映射、别名、路线策略和热点点位;
- 规划服务据此构建候选花点、候选补给点和候选终点集合;
- 后续的路径规划在这些候选集上继续进行。
4.4 多阶段自然语言路线规划
本项目的核心在于把自然语言请求转化为一条“可走、可解释、可展示”的多阶段路线。相关实现位于cloudbase-agent-service/src/demo-planner.ts,其主流程如下:
export async function planDemoRoute(input: DemoPlannerRequest) {
const sceneId = input.sceneId || process.env.DEFAULT_SCENE_ID || "tsinghua-spring";
const scene = getSceneProfile(sceneId);
const pois = getScenePois(sceneId);
const flowerHotspots = getSceneFlowerHotspots(sceneId);
const semanticStops = uniqueStops([...pois, ...flowerHotspots]);
const { intent, taskPlan, routerDebug } = await maybeRefineIntent({ ...input, sceneId }, scene, pois);
const routeStart = await resolveRouteStart(input.startPoint, scene, pois);
const scenicSelection = await selectScenicStopsWithLLM({
userQuery: intent.rawQuery,
scenicQuery: intent.scenicQuery || buildDefaultScenicQuery(intent),
scenicCount: scenicLimit,
anchor: routeStart,
candidates: scenicCandidatePool,
sceneName: scene.sceneName,
intent,
});
if (!resolvedLunchTarget && (intent.wantsLunch || lunchSearchPlans.length)) {
toolCalls.push({ tool: "placeSearchText", purpose: "在赏花段附近搜索食堂或午餐补给点" });
}
const routing = await fetchWalkingRoute([routeStart, ...normalizedStops]);
toolCalls.push({ tool: "directionWalking", purpose: "为多段停留点生成真实步行路线" });
return {
type: "route_plan",
sceneId,
summary,
decisionTrace,
toolCalls,
segments,
mapOverlays: {
markers: normalizedStops.map((stop) => ({ name: stop.name, lat: stop.lat, lng: stop.lng })),
polylines: [{ label: "recommended-walk", coordinates: routing.mergedPolyline }],
},
};
}
把这段代码展开来看,路径规划过程可以拆为下表中的九个步骤:
通过上述链路,系统可以把“我想看粉色的花,走一段时间,再找地方吃午饭,最后去适合休息的地点”这样的自然语言请求分解为:
- 前半程赏花阶段;
- 中间补给阶段;
- 后半程收尾阶段。
如果进一步细化到字段级别,Agent对用户输入的映射关系可以表示为下表:
随后,系统再根据每一阶段的目标生成对应的segments、地图标记和路线折线。这一实现方式使得规划结果具备了可执行性,而不仅仅是推荐若干零散地点。
4.5 结构化输出与ToolCard渲染
为了让规划结果能够被前端直接可视化,系统在prompts.ts中定义了统一的结构化输出契约:
export const ROUTE_PLAN_JSON_CONTRACT = `
{
"type": "route_plan",
"sceneId": "tsinghua-spring",
"userIntent": "原始用户问题",
"routeTitle": "AI 为你整理的路线标题",
"summary": "一句话总结",
"decisionTrace": ["意图拆解步骤 1", "意图拆解步骤 2"],
"toolCalls": [
{ "tool": "get_scene_profile", "purpose": "读取校园语义" },
{ "tool": "directionWalking", "purpose": "生成步行路线" }
],
"segments": [...],
"insights": {...},
"mapOverlays": {...}
}
`;
这样一来,前端就能够直接渲染路线结果,而不需要再从长文本中二次抽取信息。ToolCard侧的渲染逻辑如下:
function renderRouteSegments(payload: any) {
const segments = Array.isArray(payload?.segments) ? payload.segments : [];
if (!segments.length) return null;
return (
<ul className="segment-list">
{segments.slice(0, 4).map((segment: any, index: number) => (
<li className="segment-item" key={`${segment?.title || "segment"}-${index}`}>
<strong>{segment?.title || `第 ${index + 1} 段`}</strong>
<p>{segment?.objective || "路线阶段说明待补充"}</p>
<div className="pill-row">
{segment?.durationText ? <span className="pill">{segment.durationText}</span> : null}
{segment?.distanceText ? <span className="pill">{segment.distanceText}</span> : null}
</div>
</li>
))}
</ul>
);
}
这一部分把服务端返回的路线段、距离、时长、推荐理由和POI结果组织成统一卡片视图。对于城市赏花地图来说,ToolCard的重要性体现在两个方面:
- 它把“模型输出”转化成了“界面组件”;
- 它让用户在看地图的同时,也能看到每一段路线为什么这样规划。
4.6 花况共建与云端数据更新
为了让赏花地图能够持续更新,系统在前端定义了标准化的花况共建对象。相关代码位于src/app.js:
const contribution = {
id: `community-${Date.now()}`,
type: "phenology",
source: "community",
relatedId: linkedSpot?.id || null,
timestamp: formatTodayTime(new Date(createdAt)),
title: `${locationName} 的 ${species} ${bloomStage}`,
note,
mediaCount: imageUrl ? 1 : 0,
species,
bloomStage,
bloomScore: BLOOM_STAGE_SCORE[bloomStage] || 80,
imageUrl,
lat: basePoint?.lat,
lng: basePoint?.lng,
locationName,
createdAt,
};
上述对象通过云端服务写入flower_reports与flower_photos等集合,并进入审核流。随后,系统按以下流程刷新花况数据:
- 用户在地图上选点并填写花种、花期状态、图片和备注;
- 前端生成标准化花况对象并提交到云端;
- 云端写入待审核记录;
- 审核通过后更新正式花况层;
- 聚合任务刷新flowerSummary与热点样本;
- 路线规划服务在下一轮推荐中优先使用最新花况数据。
这条链路使城市赏花地图具备持续演化能力。随着用户提交花况和路线反馈,系统中的季节点位热度、推荐顺序和热点区域也会动态变化。
5. 案例验证:以清华大学春季赏花场景为例
5.1 场景数据与功能组成
为验证系统在真实场景中的可用性,本文选取清华大学春季赏花区域作为实验样区,构建了包含核心赏花点、补给点、休息点、图片资源、热点样本与用户共建入口的完整demo。
其中,花况地图由团队成员手动于ArcGIS Pro中标注并进行坐标导出,图片来源于小红书。
清华大学验证样区中,系统主要展示以下功能模块:
5.2 典型交互流程
在清华大学demo中,用户可以按照如下方式完成一次完整交互:
- 打开城市赏花地图主页,浏览当前热点花点与推荐路线;
- 在输入框中给出自然语言请求,例如“我想看粉色的花,然后去清华大学紫荆食堂”;前端调用路线规划服务,请求Agent进行任务拆解和工具调用;服务端返回结构化路线JSON,前端同步展示路线步骤、地图标记、路线摘要和ToolCard。
- 用户继续追问或切换视图,查看不同路线、不同点位和不同解释结果;
- 用户在共建面板中提交新的花况信息,地图与动态列表刷新。
这一流程覆盖了本项目的核心功能:花点位展示、自然语言规划、路线回填、结果解释、用户共建和动态更新。
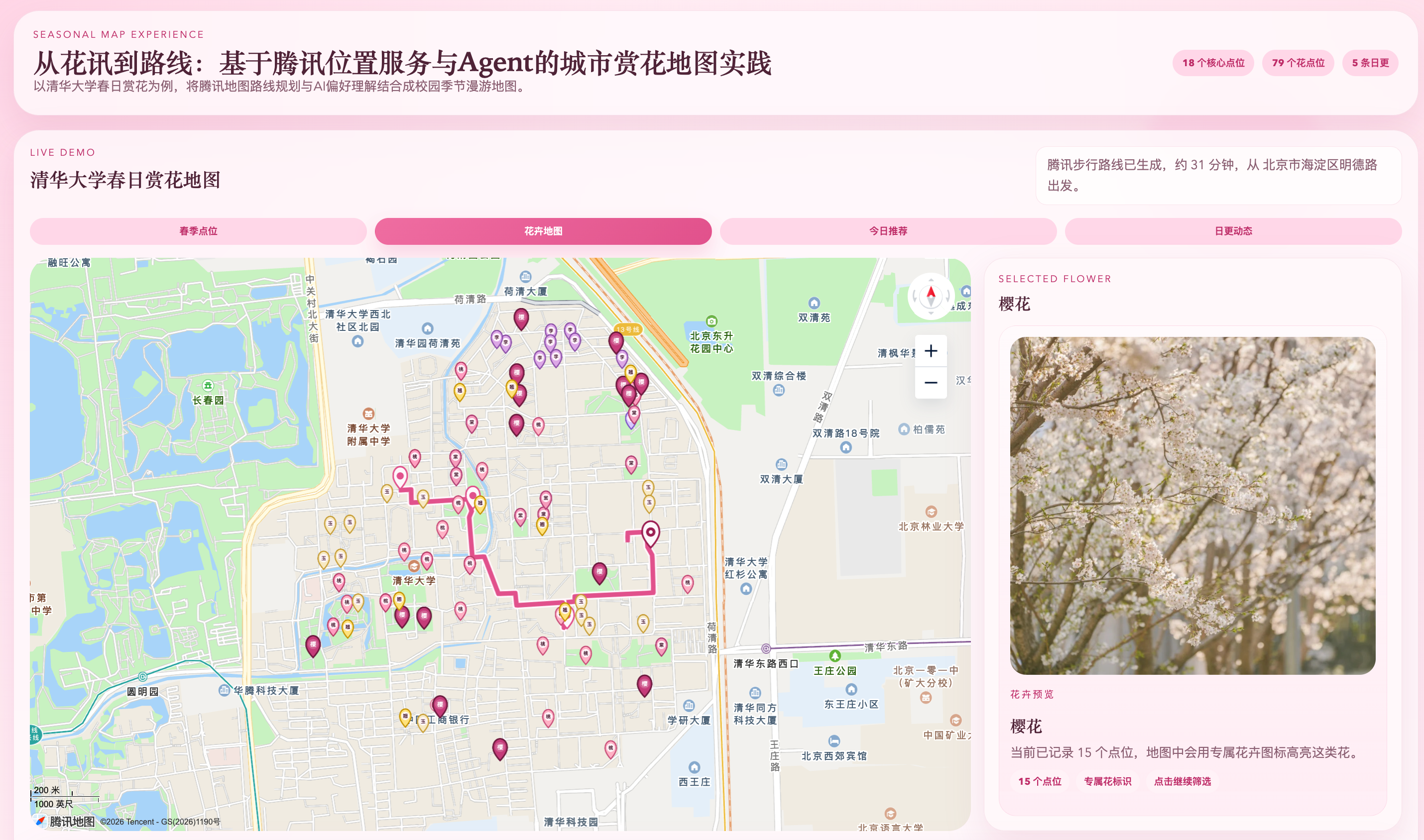
5.3 清华大学demo中的核心页面展示
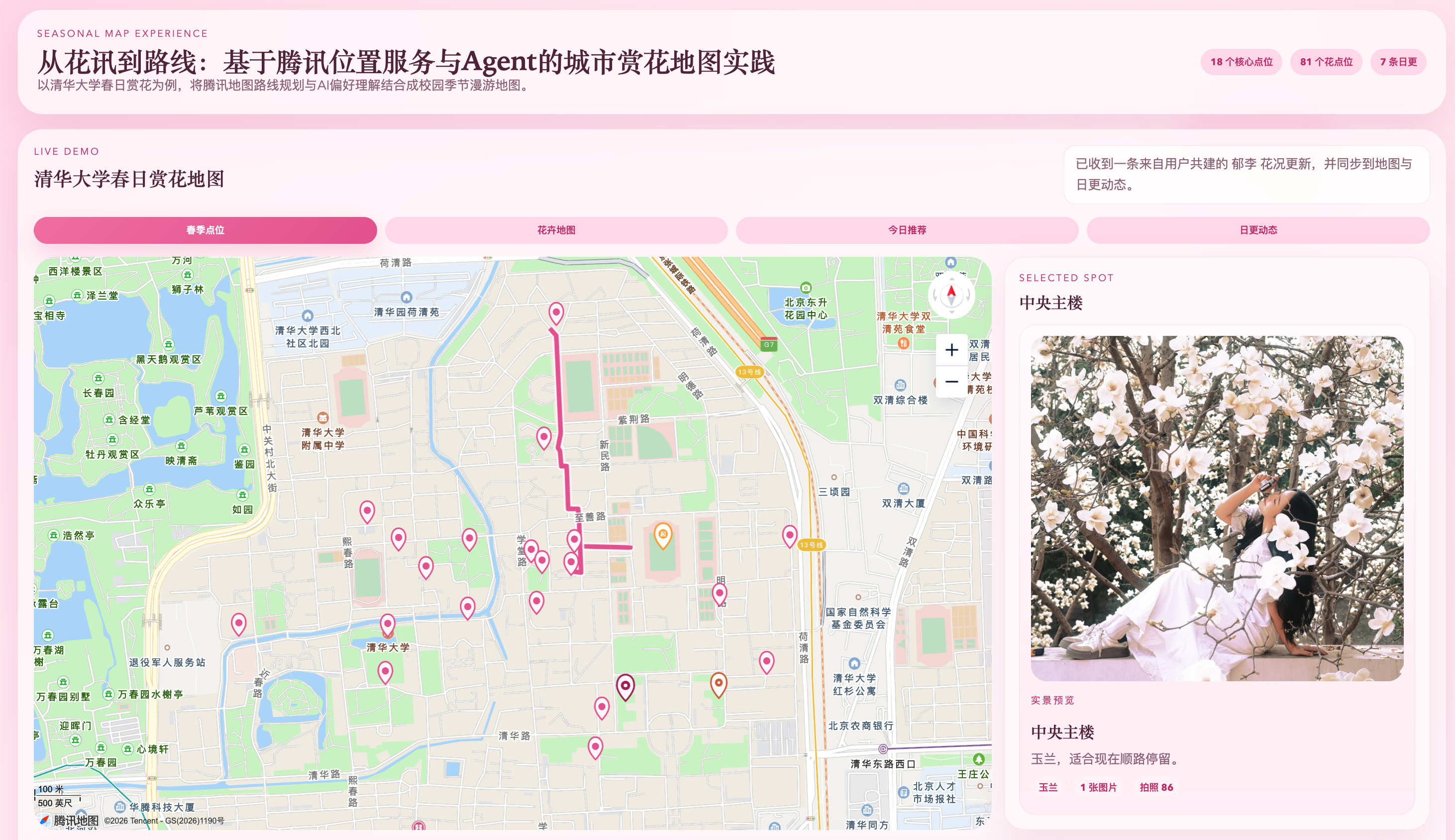
图5-1 城市赏花地图首页总览。
(2)花点位与赏花图层
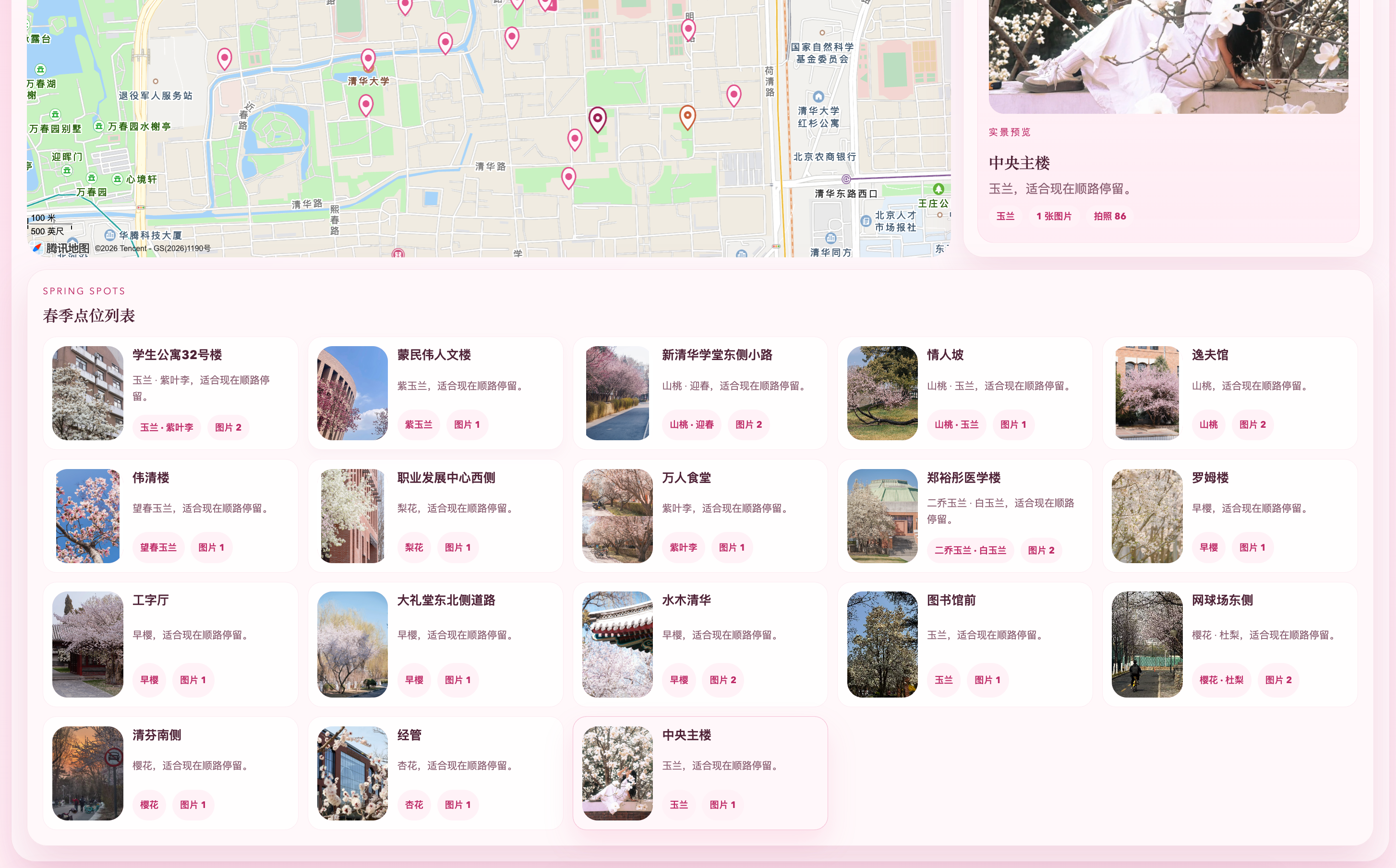
图5-2 清华大学春季花点位展示,可直观看到核心赏花点与代表性观赏区域。
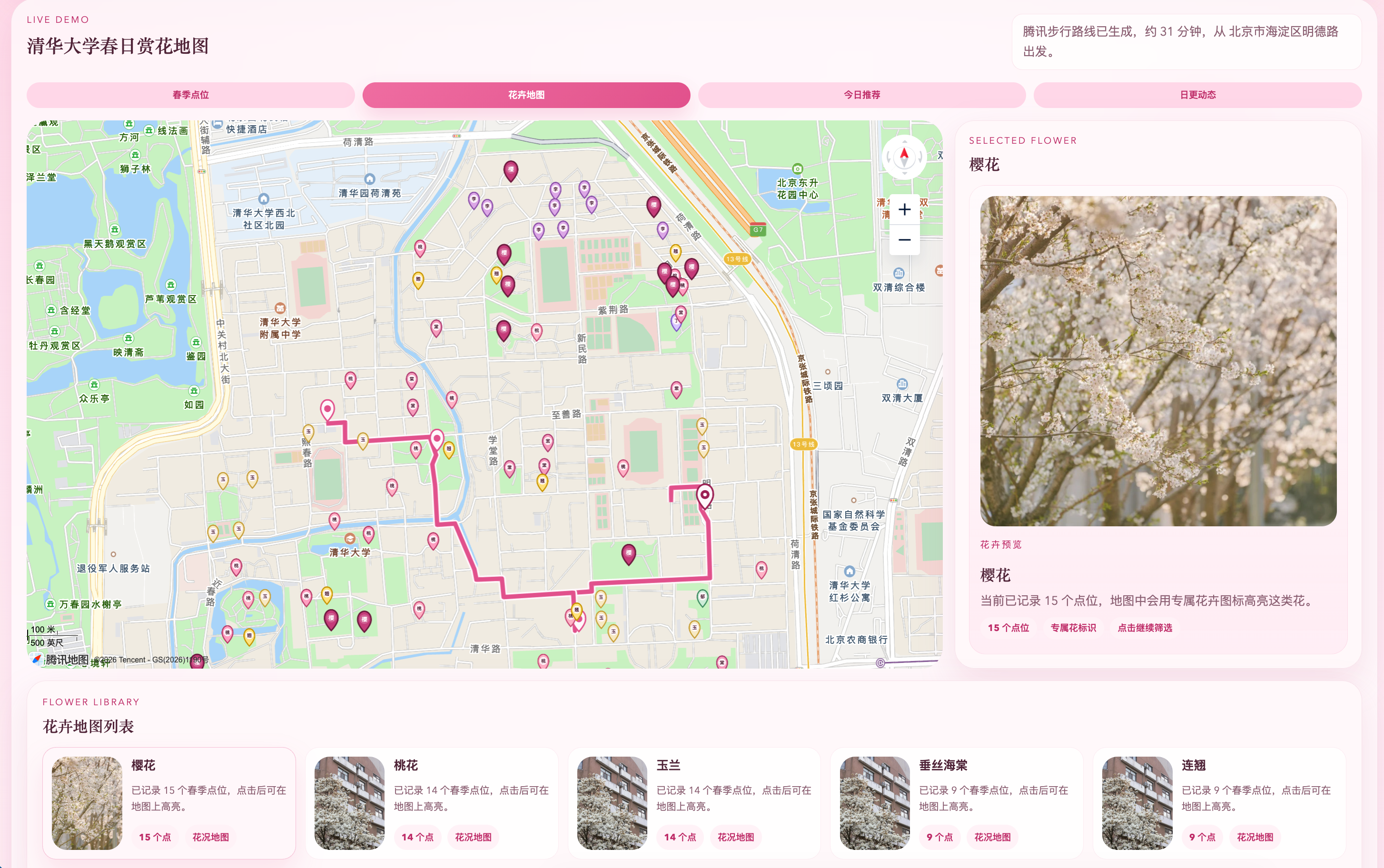
图5-3 清华大学花卉地图展示。
(3)自然语言规划面板
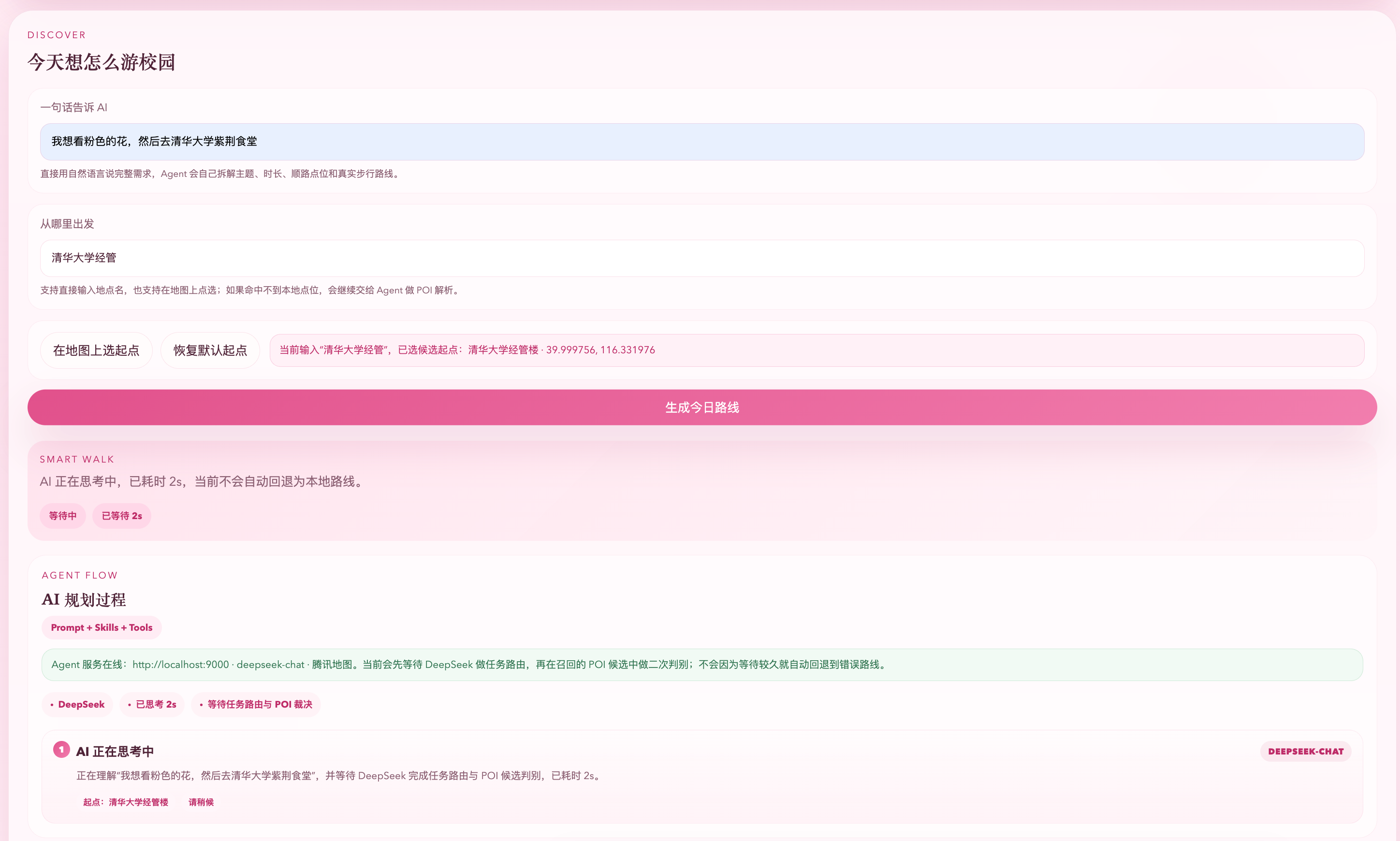
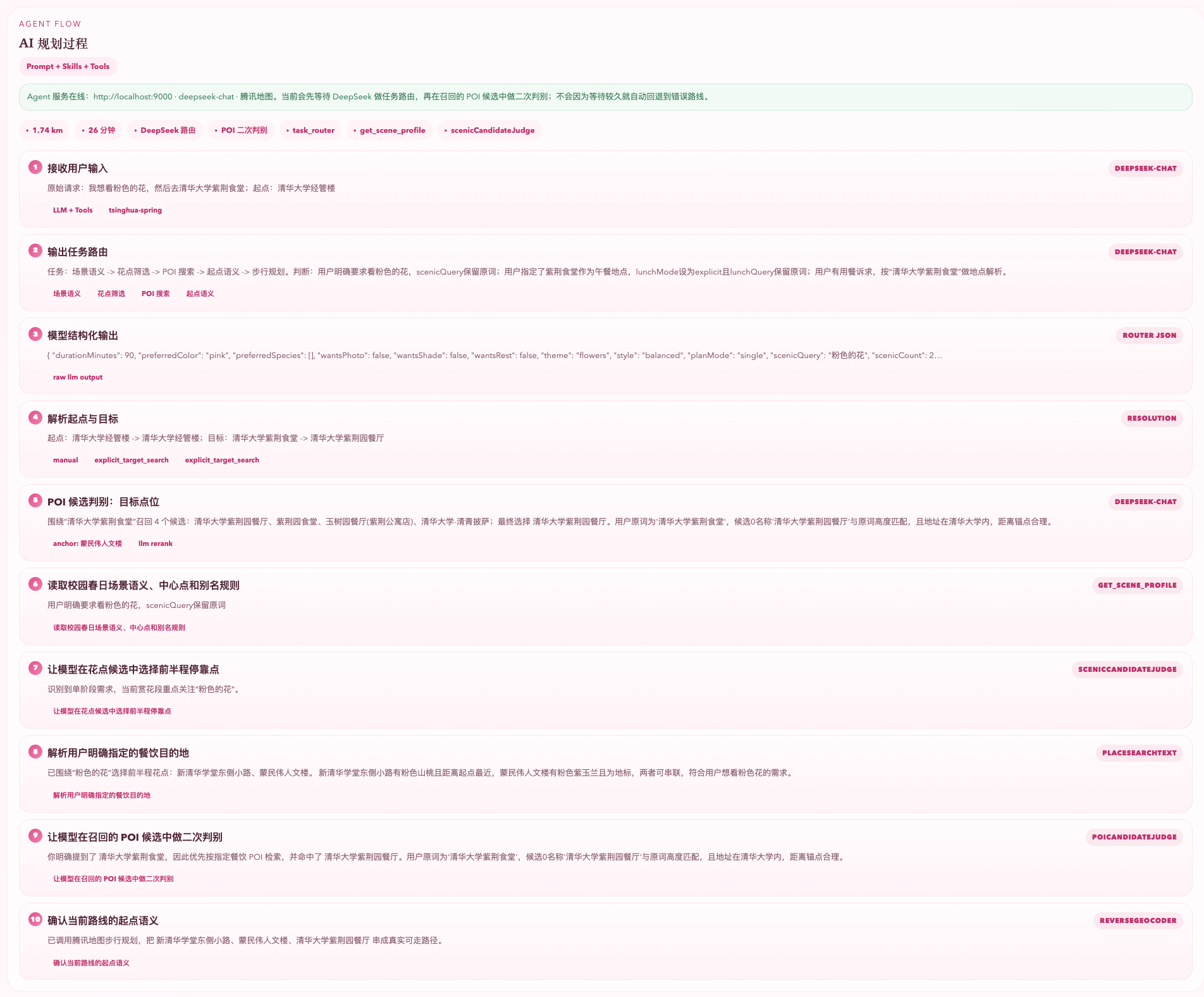

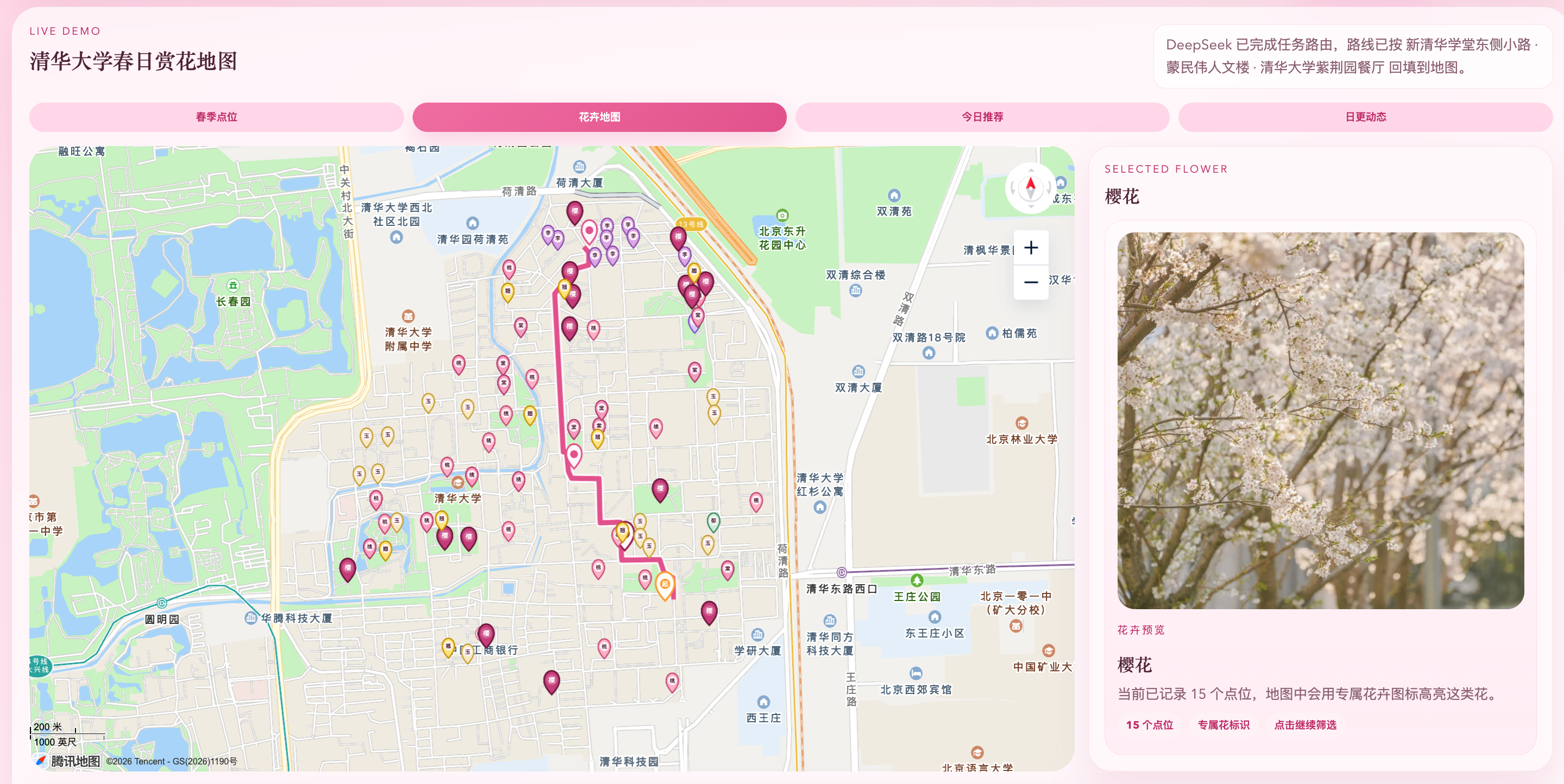
图5-4 规划结果与ToolCard展示。
6. 创新点概括
与常规地图展示型作品相比,本文方案的创新点主要体现在以下四个方面:
6.1 从零散花讯整合为统一赏花入口
系统以城市赏花地图为载体,将社交平台、攻略帖、用户上报和地图点位信息整合为统一交互入口,解决了花讯分散、信息松散和路线难以组织的问题。
6.2 从点位展示扩展为可解释路线规划
系统通过Agent任务拆解、场景语义工具与腾讯地图步行规划,将“看什么花、怎么走、是否顺路吃饭、最后去哪里休息”组织成一条多阶段路线,并保留详细解释过程。
6.3 从静态花点扩展为动态花况系统
系统引入季节性花况层、用户共建层与审核聚合机制,使地图内容能够随时间持续更新,路线推荐也可以基于最新花况进行动态调整。
6.4 从单一案例扩展为城市级可迁移架构
虽然本文以清华大学为验证场景,但系统底层已经按“场景画像层、动态花况层、规划服务层、卡片结果层”进行组织,具备向城市公园、城市绿道、城市花海等更多季节性场景扩展的潜力。
7. 结语
本文围绕城市赏花地图场景,提出并实现了一套融合腾讯位置服务、Agent规划能力、场景语义工具与动态花况共建机制的智能地图系统。系统以自然语言复合需求为输入,通过场景语义建模、候选点裁决、真实步行路线生成与ToolCard可视化输出,构建了从需求理解到结果呈现的完整技术链路。
在清华大学春季赏花场景的案例验证中,系统完整展示了花点位组织、自然语言规划、分段路线生成、卡片化结果展示和花况共建更新等关键功能。更重要的是,这套方案已经具备城市级扩展所需的数据组织方式、服务结构和交互模式,可以继续向多区域、多季节的城市赏花服务延展。

